MapReduce是面向大数据并行处理的计算模型、框架和平台,对于大数据开发或者想要接触大数据开发的开发者来说,是必须要掌握的,它是一种经典大数据计算框架,现在有很多开源项目的内部实现都会直接或间接地借鉴了MR过程的实现。Hadoop中的MapReduce 是一个离线批处理计算框架。
1)MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
2)MapReduce是一个并行计算与运行软件框架(Software Framework)。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
3)MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理 。
1 实现流程
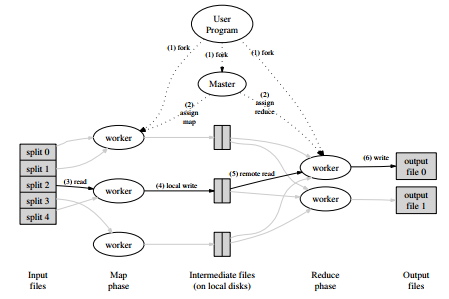
上图所示为实现MapReduce操作的总体流程:
1) 用户程序首先调用的MapReduce库将输入文件分成M个数据片段,每个数据片段的大小一般从 16MB到64MB(可以通过可选的参数来控制每个数据片段的大小)。然后用户程序在集群中创建大量的程序副本。
2) 这些程序副本中有一个特殊的master程序副本,其它的都是worker程序,由master分配任务。有M个Map任务和R个Reduce任务将被分配,master将分配空间的worker来执行每一个Map任务或Reduce任务。
3) 被分配了map任务的worker程序(Map worker)读取相关的输入数据片段,从输入的数据片段中解析出键值对,然后把键值对传递给用户自定义的Map函数,生成并输出的中间键值对,并缓存在内存中。
4) 缓存中的键值对通过分区函数分成R个区域,之后周期性的写入到本地磁盘上。缓存的键值对在本地磁盘上的存储位置将被回传给master,由master负责把这些存储位置再传送给Reduce worker。
5) 当Reduce worker程序被通知到由master程序发来的数据存储位置信息后,使用RPC从Map worker所在主机的磁盘上读取这些缓存数据。当Reduce worker读取了所有的中间数据后,通过对key进行排序后使得具有相同key值的数据聚合在一起。由于许多不同的key值会映射到相同的Reduce任务上,因此必须进行排序。如果中间数据太大无法在内存中完成排序,那么就要在外部进行排序。
6) Reduce worker程序遍历排序后的中间数据,对于每一个唯一的中间key值,Reduce worker程序将这个key值和它相关的中间value值的集合传递给用户自定义的Reduce函数。Reduce函数的输出被追加到所属分区的输出文件。
当所有的Map和Reduce任务都完成之后,master唤醒用户程序。在这个时候,在用户程序里的对MapReduce调用才返回。
2 阶段划分
2.1 提交客户作业
作业提交通过网络完成,框架将输入数据集划分块,即输入分片(input split),以便并行处理。
2.2 执行Map任务
每一个输入分片都会对应一个map任务,该任务对分片中的每一条记录运行用户提供的map函数。格式化输入负责将每一条记录转换成对应的键值对表示法(例如:有一种内建的输入格式,它能将文件的每一行转换成值并以文件偏移值为键),map函数用键值对来作为输入并产生零个或多个中间键值对。
在map任务处理完之后,首先会将这个结果写入到内存缓存区中(缓冲区的作用就是批量收集Map结果,减少磁盘I/O影响),也就是在内存中会划分出一片区域来存储map任务处理完的数据结果,内存缓冲区的大小是有限的,默认是100MB。当写入的数据所占大小占整个环形缓冲区的80%之后,就开始把缓冲区中的数据写入到本地磁盘文件中,即溢写。在写出的过程中,map的处理结果仍然会向缓冲区中写入,这个过程可以看做是一个环状,所以称之为环形缓冲区,其实在内存中就是一个数组。
写出数据之前,每一个键会被一个称作为分区器(partitioner)的组件分配到一个分区(partition)。默认实现是一个哈希分区器:将键的哈希值与作业所配置的reduce任务数目进行取模从而得到一个分区号。然后在分区内按照键进行排序,排好序之后再将内存中的数据写入到文件中。因为在内存中已经对分区内的数据进行排序,所以写出到文件中的数据在分区内是有序的,如果map任务产生的结果比较大,就会不断地将缓冲区中的数据溢写到文件中,根据数据量的大小就会产生多个文件,这些文件当中的数据是分区的,且分区内是有序的。
当map任务运行完成后,会将所有输出的这些小文件合并成一个大的文件,在合并文件的过程中还是会对分区内的文件进行排序。
注意:在执行map任务时,combine操作是可选的,它是一个本地化的reduce操作,是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作,目的是为了减少网络传输数据,提高带宽的传输效率。
2.3 shuffle和排序
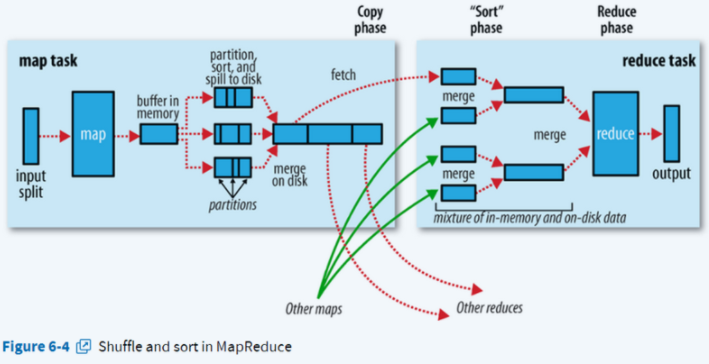
在MapReduce过程中需要各节点上的同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则聚集到一起的过程称为Shuffle。(也有说shuffle是从map输出结果开始的,按个人理解来)当reduce任务开始的时候,reduce任务就会通过RPC请求map任务所在的节点获取属于它的输出文件。当把所有的数据都拷贝过来后,就会将这些数据合并,map的输出数据是有序的,因此在reduce端进行合并是采用归并排序,合并之后就会将相同的键的数据分到一组,不同的键之间进行排序,最终会形成一个键对应一组值这样一组数据。
2.4 执行reduce任务
当分区数据被合并成一个完整的有序列表后,用户的reduce代码就开始被执行。每一个reduce任务都会产生一个单独的输出文件,通常存储在HDFS中。独立的输出文件使得reduce任务之间无需协调共享文件的访问,大大减少了reduce的复杂性并能让每一个reduce任务运行效率最大化。输出文件的格式取决于Output format参数,参数在MapReduce的用户在作业配置中指定。
3 应用场景
1、进行数据统计,比如计算大型网站的浏览量;
2、搜素引擎中索引的创建Google最早使用MapReduce就是对每天爬取的几十亿上百亿的网页创建索引,从而产生的MapReduce框架);
3、海量数据中查找出具有某些特征的数据;
4、复杂数据分析算法的实现(比如聚类,分类算法,推荐算法。这些算法需要大量的训练数据来训练算法模型,一些算法集成工具使用MapReduce使程序跑在分布式系统环境中)。
注意:
通过前面的介绍,我们可以发现MapReduce更适合处理海量数据的分布式批量离线处理,所以也就限制了它的使用。下面的场景不适合使用MapReduce:
1. 低延迟实时计算,这种场景通常需要秒级甚至毫秒级返回计算结果。MapReduce式分布式作业的,需要分发执行任务的程序包并且在计算过程中还要在map阶段拆分数据,向Reduce传输数据,所以不能在极短时间内返回计算结果。
2. 流式计算,MapReduce自身框架设计决定了它处理输入的数据必须是静态的数据,比如说它处理存储在HDFS上的数据,HDFS上的数据是不能实时变化的。


