Python垃圾回收机制是什么
作为Python的使用者来说,Python中的垃圾回收主要以引用计数为主,再引入标记、清除,分代为辅来解决循环引用的问题。
一个对象被引用时,引用计数加1,当对象被del时,引用计数减去1,为0时,对象就被清除,一般情况下用户不会去操作Python的垃圾回收机制,但它留有API接口。
元组和列表的区别
主要区别是列表是可变的,而元组是不可变的。
>>> mylist=[1,3,3]
>>> mylist[1]=2
>>> mytuple=(1,3,3)
>>> mytuple[1]=2
Traceback (most recent call last):
File "<pyshell#97>", line 1, in <module>
元组可以作为字典的key?
首先一个对象能不能作为字典的key, 就取决于其有没有__hash__方法。 所以除了容器对象(list/dict/set)和内部包含容器对象的tuple是不可作为字典的key,其他的对象都可以。
进程-线程-协程
进程
操作系统进行资源分配和调度的基本单位,多个进程之间相互独立
稳定性好,如果一个进程崩溃,不影响其他进程,但是进程消耗资源大,开启的进程数量有限制
线程
CPU进行资源分配和调度的基本单位,线程是进程的一部分,是比进程更小的能独立运行的基本单位,一个进程下的多个线程可以共享该进程的所有资源
如果IO操作密集,则可以多线程运行效率高,缺点是如果一个线程崩溃,都会造成进程的崩溃
协程
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
赋值、浅拷贝和深拷贝
深拷贝就是将一个对象拷贝到另一个对象中,这意味着如果你对一个对象的拷贝做出改变时,不会影响原对象。在Python中,我们使用函数deepcopy()执行深拷贝。
浅拷贝则是将一个对象的引用拷贝到另一个对象上,所以如果我们在拷贝中改动,会影响到原对象。
GIL
GIL是Python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行Python程序的时候会霸占Python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个Python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大。
列表去重
先通过转换为集合去重,在转列表。
最常用的排序算法及其复杂度
冒泡排序
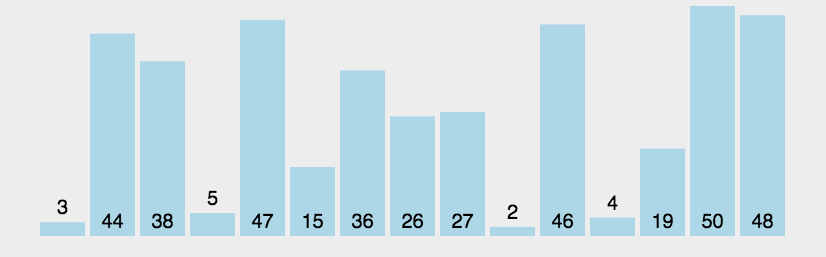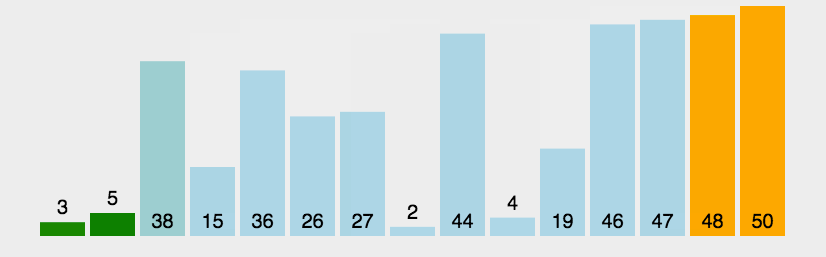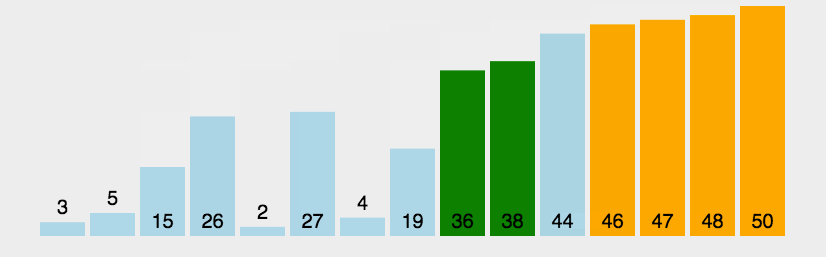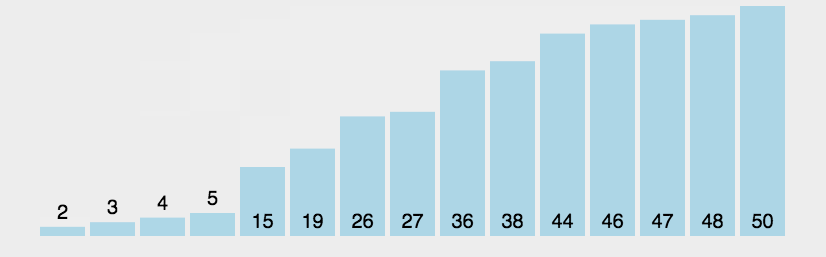
外层循环从1到n-1,内循环从当前外层的元素的下一个位置开始,依次和外层的元素比较,出现逆序就交换,通过与相邻元素的比较和交换来把小的数交换到最前面。
def bubbleSort(array):
if len(array) < 2:
return array
else:
isSorted = False
counter = 0
while not isSorted:
isSorted = True
for idx in range(len(array) - 1 - counter):
if array[idx] > array[idx + 1]:
isSorted = False
(array[idx + 1], array[idx]) = (array[idx], array[idx + 1])
counter += 1
return array
快速排序
通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
选定Pivot中心轴
从R指针开始,将大于Pivot的数字放在Pivot的右边
将小于Pivot的数字放在Pivot的左边
分别对左右子序列重复前三步操作
def quickSort(array):
print(array)
if len(array) < 2:
return array
else:
pivot_index = 0
pivot = array[pivot_index]
less_part = [i for i in array[pivot_index+1:] if i <= pivot]
large_part = [i for i in array[pivot_index+1:] if i > pivot]
return quickSort(less_part) + [pivot] + quickSort(large_part)
闭包
函数的返回值是函数对象,只有外部函数才可以对他进行访问,提高了安全性
with
with语句的使用,可以简化代码,有效避免资源泄露的发生。
打开文件在进行读写的时候可能会出现一些异常状况,如果按照常规的f.open写法,我们需要try,except,finally,做异常判断,并且文件最终不管遇到什么情况,都要执行finally f.close()关闭文件,with方法帮我们实现了finally中f.close。
实例方法 静态方法
实例方法只能被实例调用,静态方法(@由staticmethod装饰器的方法)、类方法(由@classmethod装饰器的方法),可以被类或类的实例对象调用。
实例方法,第一个参数必须要默认传递实例对象,一般使用self。
静态方法,参数没有必要。
类方法,第一个参数必须要默认传递,一般使用cls。
迭代器和生成器
迭代器
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter()和next()。
字符串,列表或元组对象都可用于创建迭代器:
>>> list=[1,2,3,4]
>>> it = iter(list) # 创建迭代器对象
>>> print (next(it)) # 输出迭代器的下一个元素
1
>>> print (next(it))
2
>>>
生成器
使用了yield的函数被称为生成器。
生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器,在调用生成器运行的过程中,每次遇到yield时函数会暂停并保存当前所有的运行信息,返回yield的值,并在下一次执行next()方法时从当前位置继续运行
匿名函数
print [(lambda x:x*x)(x)for x in range(5)]
[0, 1, 4, 9, 16, 25]
Map、Reduce、Filter
Map
对可迭代对象中的每个元素进行相同的操作。
def fn(x):
return x+1
resp = map(fn,li)
print(list(resp))
[2, 3, 4]
Reduce
从左到右对一个序列的项累计地应用有两个参数的函数,以此合并序列到一个单一值。(例如累加或累乘列表元素等等)
from functools import reduce
nums=[1, 2, 3, 4]
def fn(x, y):
return x * y
resp = reduce(fn, nums)
print(resp)
24
Filter
Filter函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该接收两个参数:第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回True或False,最后将返回True的元素放到新列表。
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def fn(a):
return a%2 == 1
newlist = filter(fn, a)
newlist = [i for i in newlist]
print(newlist)
## 输出: [1, 3, 5, 7, 9]
Django
什么是WSGI
Python Web Server Gateway Interface,翻译过来是Python Web服务器网关接口,实际上就是一种协议,我们的应用(Django,Flask)实现了WSGI,就可以配合实现了WSGI(uWSGI,gunicorn)的服务器工作了
Django请求的生命周期
前端发送请求
WSGI,他就是socket服务端,用于接收用户请求并将请求进行初次封装,然后将请求交给Web框架(Flask、Django)
中间件处理请求,帮助我们对请求进行校验或在请求对象中添加其他相关数据,例如:CSRF、request.session
路由匹配,根据当前请求的URL找到视图函数,如果是FBV写法,通过判断method两类型,找到对应的视图函数;如果是CBV写法,匹配成功后会自动去找Dispatch方法,然后Django会通过Dispatch反射的方式找到类中对应的方法并执行
视图函数,在视图函数中进行业务逻辑的处理,可能涉及到:orm、view视图将数据渲染到template模板
视图函数执行完毕之后,会把客户端想要的数据返回给Dispatch方法,由Dispatch方法把数据返回经客户端
中间件处理响应
WSGI,将响应的内容发送给浏览器
浏览器渲染
列举Django的内置组件
Admin:对model中对应的数据表进行增删改查提供的组件
model:负责操作数据库
form:1. 生成HTML代码;2. 数据有效性校验;2. 校验信息返回并展示
ModelForm:即用于数据库操作,也可用于用户请求的验证
列举Django中间件的5个方法?以及Django中间件的应用场景
process_request:请求进来时,权限认证
process_view:路由匹配之后,能够得到视图函数
process_exception:异常时执行
process_template_responseprocess:模板渲染时执行
process_response:请求有响应时执行
简述什么是FBV和CBV
FBV和CBV本质是一样的,基于函数的视图叫做FBV,基于类的视图叫做CBV。
在Python中使用CBV的优点:
提高了代码的复用性,可以使用面向对象的技术,比如Mixin(多继承)
可以用不同的函数针对不同的HTTP方法处理,而不是通过很多if判断,提高代码可读性
Django的Request对象是在什么时候创建的
class WSGIHandler(base.BaseHandler):
request = self.request_class(environ)
请求走到WSGIHandler类的时候,执行cell方法,将environ封装成了Request。
如何在CBV添加装饰器
方法
from django.utils.decorators import method_decorator
@method_decorator(check_login)
def post(self, request):
...
Dispatch
@method_decorator(check_login)
def dispatch(self, request, *args, **kwargs):
类
@method_decorator(check_login, name="get")
@method_decorator(check_login, name="post")
class HomeView(View):
...
列举Django ORM中所有的方法
<1> all(): 查询所有结果
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象。获取不到返回None
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个。
如果符合筛选条件的对象超过一个或者没有都会抛出错误。
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
<5> order_by(*field): 对查询结果排序
<6> reverse(): 对查询结果反向排序
<8> count(): 返回数据库中匹配查询(QuerySet)的对象数量
<9> first(): 返回第一条记录
<10> last(): 返回最后一条记录
<11> exists(): 如果QuerySet包含数据,就返回True,否则返回False
<12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的
并不是一系 model的实例化对象,而是一个可迭代的字典序列
<13> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
<14> distinct(): 从返回结果中剔除重复纪录
select_related和prefetch_related的区别
有外键存在时,可以很好的减少数据库请求的次数,提高性能,select_related通过多表join关联查询,一次性获得所有数据,只执行一次SQL查询prefetch_related分别查询每个表,然后根据它们之间的关系进行处理,执行两次查询。
Django中CSRF的实现机制
第一步:Django第一次响应来自某个客户端的请求时,后端随机产生一个Token值,把这个Token保存在Session状态中;同时,后端把这个Token放到cookie中交给前端页面。
第二步:下次前端需要发起请求(比如发帖)的时候把这个Token值加入到请求数据或者头信息中,一起传给后端;Cookies:{csrftoken:xxxxx}
第三步:后端校验前端请求带过来的Token和Session里的Token是否一致。
Django中如何实现ORM表中添加数据时创建一条日志记录
# 使用Django的信号机制,可以在添加、删除数据前后设置日志记录:
pre_init # Django中的model对象执行其构造方法前,自动触发
post_init # Django中的model对象执行其构造方法后,自动触发
pre_save # Django中的model对象保存前,自动触发
post_save # Django中的model对象保存后,自动触发
pre_delete # Django中的model对象删除前,自动触发
post_delete # Django中的model对象删除后,自动触发
# 使用
@receiver(post_save, sender=Myclass) # 信号接收装饰器。由于内置信号,所以直接接收
def signal_handler(sender, **kwargs):# 接收到信号后,在此处理
logger = logging.getLogger()
logger.success('保存成功')
Django缓存如何设置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.dummy.DummyCache', # 缓存后台使用的引擎
'TIMEOUT': 300, # 缓存超时时间(默认300秒,None表示永不过期,0表示立即过期)
'OPTIONS':{
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
},
}
}
Django的缓存能使用Redis吗?如果可以的话,如何配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}
# "PASSWORD": "密码",
}
}
}
Django路由系统中name的作用
主要是通过name的值,来查找url地址,可以理解为反射作用。在html模板中使用name来反射url优势就是后期url规则发生改变之后,只需调整urls.py即可,所有的模板文件都不需要修改。
Django REST Framework框架中都有那些组件
认证
权限(授权)
用户访问次数/频率限制
版本
解析器(parser)
序列化
分页
路由系统
视图
渲染器
简述Django REST Framework框架的认证流程
当用户进行登录的时候,运行了登录类的as_view()方法,进入了APIView类的Dispatch方法
执行self.initialize_request这个方法,里面封装了Request和认证对象列表等其他参数
执行self.initial方法中的self.perform_authentication,里面运行了user方法
再执行了user方法里面的self._authenticate()方法


